 Links sind im Internet äußerst wichtig. Eingehende Links bringen Besucher auf die Seite. Ausgehende Links ermöglichen es den eigenen Besuchern, weitergehende Informationen auf anderen Seiten zu erhalten. Interne Links führen den Benutzer durch die Seiten. Bei größeren Seiten kann es immer mal wieder passieren, dass hier und da eine Datei gelöscht wird, die von einer anderen Seite noch verlinkt ist. Wie man einfach solche gelöschten Dateien findes zeige ich hier.
Links sind im Internet äußerst wichtig. Eingehende Links bringen Besucher auf die Seite. Ausgehende Links ermöglichen es den eigenen Besuchern, weitergehende Informationen auf anderen Seiten zu erhalten. Interne Links führen den Benutzer durch die Seiten. Bei größeren Seiten kann es immer mal wieder passieren, dass hier und da eine Datei gelöscht wird, die von einer anderen Seite noch verlinkt ist. Wie man einfach solche gelöschten Dateien findes zeige ich hier.
Vielleicht hat man auch auf der eigenen Seite ein Bild gelöscht, das noch irgend wo benutzt wird. Das ist für den Besucher sehr ärgerlich. Wie man solche
Deswegen ist es eine gute Idee, die eigene Seite regelmäßig auf Broken Links zu überprüfen. Dafür gibt es eine Menge Tools, die das mehr oder weniger gut erledigen.
Es gibt aber auch ganz einfach Lösung mit dem sehr universellen Kommandozeilentool wget.
Auf den meisten Computern mit unix-artigem Betriebssystem ist das Tool schon installiert. Wenn nicht, dann kann es leicht nachgeholt werden:
Linux:
apt-get install wget
OS X, Installation mit Homebrew:
brew install wget
Windows:
Download des Installationspaketes hier: http://gnuwin32.sourceforge.net/packages/wget.htm
Jetzt kann es los gehen. Im Terminal wird folgender Befehl eingegeben:
wget --spider -o ~/wget.log -e robots=off -w 1 -r -p http://www.example.com
Der Sinn der ganzen Optionen hinter dem Befehl erschließt sich sicherlich nur den Wenigsten sofort. Deswegen will ich die mal kurz erläutern.
--spider- Die Option bewirkt, dass nicht alles heruntergeladen und gespeichert wird. Es werden also keine Bilder oder Videos übertragen. Es wird aber ein Report erstellt, ob es möglich wäre.
-o ~/wget.log- Hiermit werden die Log-Ausgaben in die Datei wget.log im Home-Ordner umgeleitet. Es ist natürlich jeder andere Dateiname möglich.
Unter Windows sollte nurwget.loggeschrieben werden, da es das Symbol “~” für den Home-Ordner nicht kennt. Die Datei wird dann im aktuellen Ordner angelegt. -e robots=off- Diese Option bewirkt, dass die Vorgaben aus der
robots.txtnicht beachtet werden. Ansonsten könne dierobots.txtfür Spider den Zugriff auf bestimmte Dateien und Ordner verbieten und unser Tool würde falsche Broken Links anzeigen. -w 1- Die Option bewirkt, dass
wgetzwischen jeder Anfrage eine Sekunde wartet. Ohne diese Option würdewgetdie Anfragen so schnell es die Hardware hergibt an den Server stellen. Dieser könnte überlastet werden. -r- Das „r“ steht für rekursiv.
wgetgeht jedem Link nach und versucht die verlinkte Datei herunterzuladen. Damit wirdwgetvon einem Programm, was einzelne Dateien herunterladen kann, zu einem Crawler. -p- Damit get
wgetallen in der HTML-Datei verlinkten Ressourcen nach, auch Bildern, PDFs oder auch CSS- oder JavaScript-Dateien. Ohne diese Option würde es nur verlinkten HTML-Datei folgen. http://www.example.com- Zum Schluss muss die URL angegeben werden, mit der
wgetmit den crawlen beginnen sollen.www.example.commuss also mit der URL der eigenen Seite ersetzt werden.
Nach einiger Zeit findet man dann im Home-Ordner die Textdatei wget.log. Öffnet man diese mit einem Editor, dann findet man ganz zum Schluss eine Liste der Broken Links.
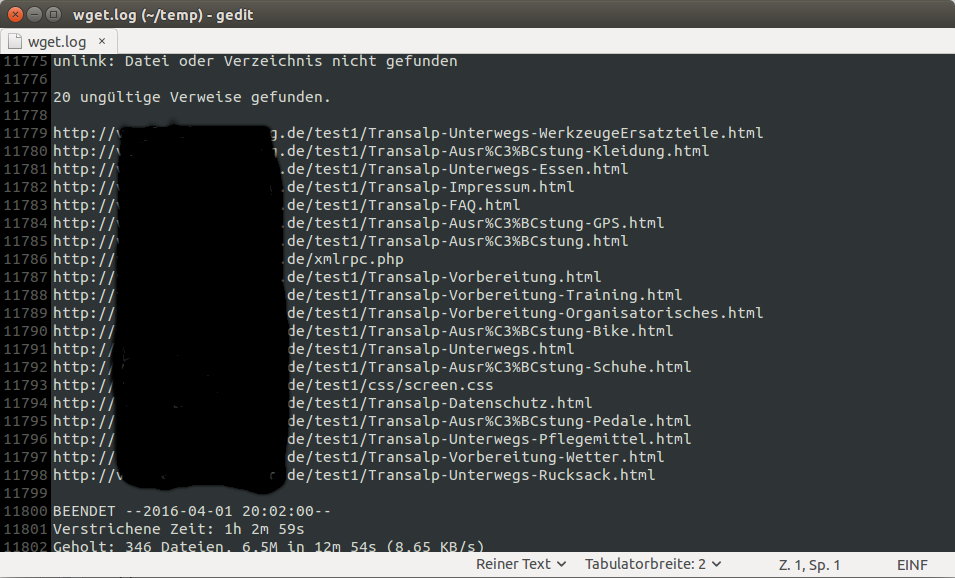
Möchte man die Ergebnisse weiter per Kommandozeile auswerten, dann ist grep das Tool der Wahl, zumindest wenn man Linux oder OS X benutzt. Windowsnutzer können alternativ findstr verwenden.
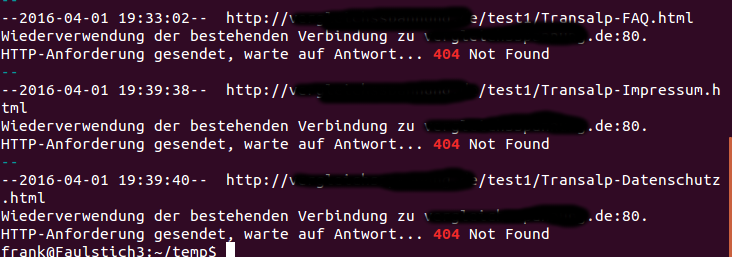
grep -B 2 ' 404 ' ~/wget.log
Die Option -B 2 zeigt nicht nur die Zeile an, die den String ' 404 ' enthält sondern auch die zwei Zeilen davor. Auf die Leerzeichen vor und nach der „404“ sollte geachtet werden. Ansonsten wird jede Zeile Ausgegeben, in der irgendwo die „404“ vorkommt.
Das Ergebnis sieht dann so aus:
Eine Stärke der Kommandozeile ist die gute Automatisierbarkeit von Abläufen. Mit sehr wenig Aufwand kann das in eine Shell-Skript eingebunden werden, das eventuell regelmäßig per cron-Job ausgeführt wird. Der Fantasie sind keine Grenzen gesetzt.
